
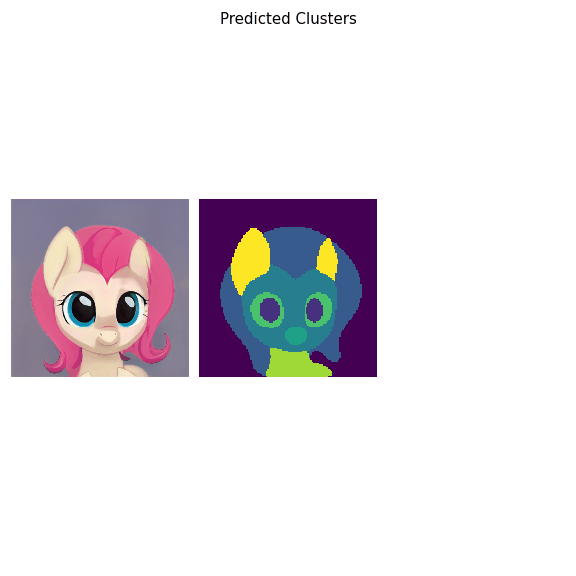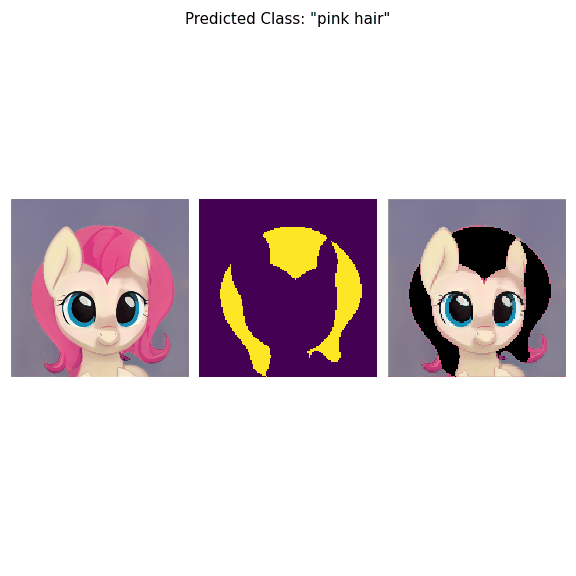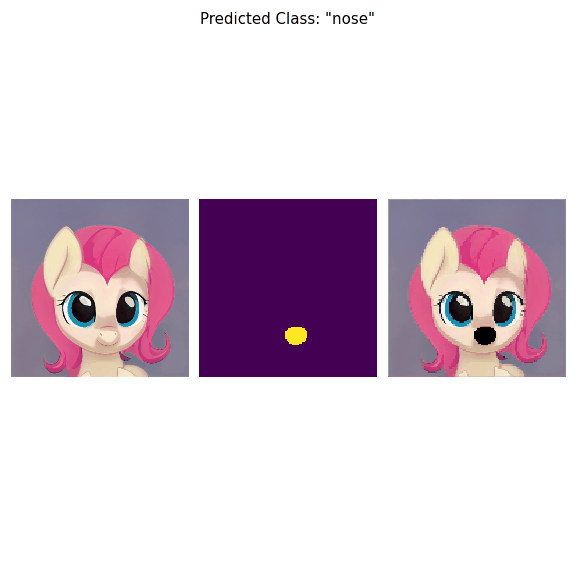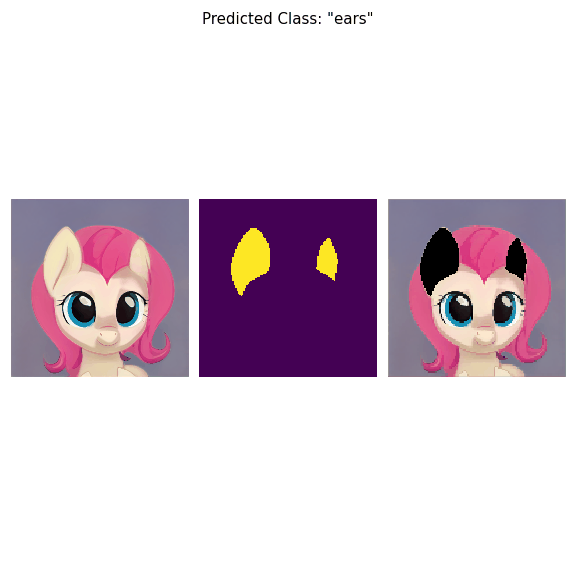
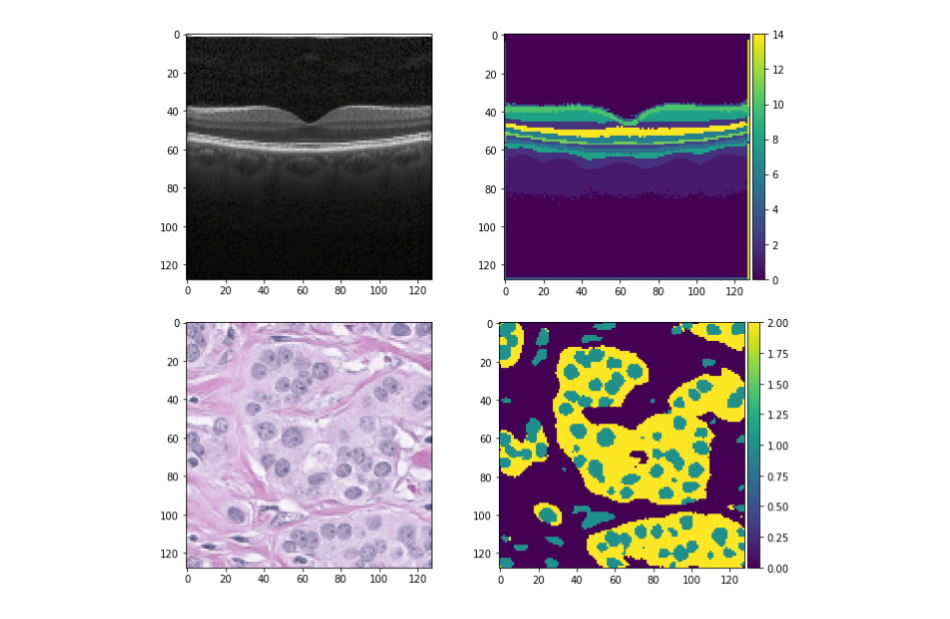
We introduce a method that allows to automatically segment images into semantically meaningful regions without human supervision.
Derived regions are consistent across different images and coincide with human-defined semantic classes on some datasets. In cases where semantic regions might be hard for human to define and consistently label, our method is still able to find meaningful and consistent semantic classes. In our work, we use pretrained StyleGAN2 generative model: clustering in the feature space of the generative model allows to discover semantic classes. Once classes are discovered, a synthetic dataset with generated images and corresponding segmentation masks can be created. After that a segmentation model is trained on the synthetic dataset and is able to generalize to real images.
Additionally, by using CLIP we are able to use prompts defined in a natural language to discover some desired semantic classes. We test our method on publicly available datasets and show state-of-the-art results.


.png?raw=true)

@article{pakhomov2021segmentation,
title={Segmentation in Style: Unsupervised Semantic Image Segmentation with Stylegan and CLIP},
author={Pakhomov, Daniil and Hira, Sanchit and Wagle, Narayani and Green, Kemar E and Navab, Nassir},
journal={arXiv preprint arXiv:2107.12518},
year={2021}
}